Think about your last trip to your local, high-volume coffee shop.
You walk up to a counter and place an order by paying for your drink. The
barista marks a cup with your order and places it in a queue, where
someone else picks it up and makes your drink. You head off to wait in a
different line (or queue) while your latte is prepared.This common, everyday exchange provides several interesting
lessons:
The coffee shop can increase the number of employees at the
counter, or increase the number of employees making coffee, with
neither action depending on the other, but depending on the
load.
The barista making coffee can take a quick break and customers
don’t have to wait for someone to take their orders. The system keeps
moving, but at a slower pace.
The barista is free to pick up different cups, and to process
more complex orders first, or process multiple orders at once.
This is a significant amount of flexibility, something that a lot of
software systems can be envious of. This is also a classic example of a
good queuing system.
There are several good uses for queues, but most people wind up
using queues to implement one important component of any scalable website
or service: asynchronous operations. Let’s illustrate this with an example
most of you should be familiar with: Twitter.
Consider how Twitter works. You publish an update and it shows up in
several places: your time line, the public time line, and for all the
people following you. When building a prototype of Twitter, it might make
sense to implement it in the simplest way possible—when you select the Update button
(or submit it through the API) you publish changes into all the
aforementioned places. However, this wouldn’t scale.
When the site is under stress, you don’t want people to lose their
updates because you couldn’t update the public timeline in a timely
manner. However, if you take a step back, you realize that you don’t need
to update all these places at the exact same time. If Twitter had to
prioritize, it would pick updating that specific user’s time line first,
and then feed to and from that user’s friends, and then the public time
line. This is exactly the kind of scenario in which queues can come in
handy.
Using queues, Twitter can queue updates, and then publish them to
the various time lines after a short delay. This helps the user experience
(your update is immediately accepted), as well as the overall system
performance (queues can throttle publishing when Twitter is under
load).
These problems face any application running on Windows Azure. Queues
in Windows Azure allow you to decouple the different parts of your
application, as shown in Figure 1.
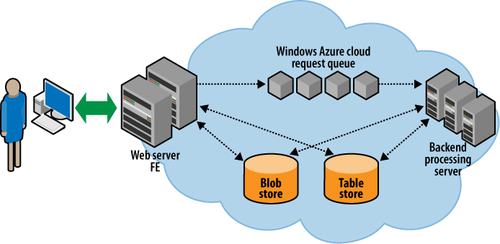
In this model, a set of frontend roles process incoming requests
from users (think of the user typing in Twitter updates). The frontend
roles queue work requests to a set of Windows Azure queues. The backend
roles implement some logic to process these work requests. They take items
off the queue and do all the processing required. Since only small
messages can be put on the queue, the frontends and backends share data
using the blob or the table storage services in Windows Azure.
Video sites are a canonical, or commonly demonstrated, usage of
Windows Azure queues. After you upload your videos to sites such as
YouTube and Vimeo, the sites transcode your videos into a format suitable
for viewing. The sites must also update their search indexes, listings,
and various other parts. Accomplishing this when the user uploads the
video would be impossible, because some of these tasks (especially transcoding from the user’s format into
H.264 or one of the other web-friendly video formats) can take a long
time.
The typical way websites solve this problem is to have a bunch of
worker process nodes keep reading requests off queues to pick videos to
transcode. The actual video files can be quite large, so they’re stored in
blob storage, and deleted once the worker process has finished transcoding
them (at which point, they’re replaced by the transcoded versions). Since
the actual work done by the frontends is quite small, the site could come
under heavy upload and not suffer any noticeable performance drop, apart
from videos taking longer to finish transcoding.
Since Windows Azure queues are available over public HTTP, like the
rest of Windows Azure’s storage services, your code doesn’t have to run on
Windows Azure to access them. This is a great way to make your code on
Windows Azure and your code on your own hardware interoperate. Or you
could use your own hardware for all your code, and just use Windows Azure
queues as an endless, scalable queuing mechanism.
Let’s break down some sample scenarios in which websites might want
to use Windows Azure queues.
1. Decoupling Components
Bad things happen in services. In large services, bad things
happen with alarming regularity. Machines fail. Software fails. Software
gets stuck in an endless loop, or crashes and restarts, only to crash
again. Talk to any developer running a large service and he will have
some horror stories to tell. A good way to make your service resilient
in the face of these failures is to make your components decoupled from
each other.
When you split your application into several components hooked
together using queues, failure in one component need not necessarily
affect failure in another component. For example, consider the trivial
case where a frontend server calls a backend server to carry out some
operation. If the backend server crashes, the frontend server is going
to hang or crash as well. At a minimum, it is going to degrade the user
experience.
Now consider the same architecture, but with the frontend and
backend decoupled using queues. In this case, the backend could crash,
but the frontend doesn’t care—it merrily goes on its way submitting jobs
to the queue. Since the queue’s size is virtually infinite for all
practical purposes, there is no risk of the queue “filling up” or
running out of disk space.
What happens if the backend crashes while it is processing a work
item? It turns out that this is OK, too. Windows Azure queues have a
mechanism in which items are taken off the queue only once you indicate
that you’re done processing them. If you crash after taking an item, but
before you’re done processing it, the item will automatically show up in
the queue after some time. You’ll learn about the details of how this
mechanism works later.
Apart from tolerating failures and crashes, decoupling components
gives you a ton of additional flexibility:
It lets you deploy, upgrade, and maintain one component
independently of the others. Windows Azure itself is built in such a
componentized manner, and individual components are deployed and
maintained separately. For example, a new release of the fabric
controller is dealt with separately from a new release of the
storage services. This is a boon when dealing with bug fixes and new
releases, and it reduces the risk of new deployments breaking your
service. You can take down one part of your service, allow requests
to that service to pile up in Windows Azure queues, and work on
upgrading that component without any overall system downtime.
It provides you with implementation flexibility. For example,
you can implement the various parts of your service in different
languages or by using different toolkits, and have them interoperate
using queues.
Note:
Of course, this flexibility isn’t unique to queues. You can
get the same effect by having standardized interfaces on
well-understood protocols. Queues just happen to make some of the
implementation work easier.
2. Scaling Out
Think back to all the time you’ve spent in an airport security line.
There’s a long line of people standing in front of a few security gates.
Depending on the time of day and overall airport conditions, the number
of security gates actually manned might go up and down. When the line
(queue) becomes longer and longer, the airport could bring more
personnel in to man a few more security gates. With the load now
distributed, the queue (line) moves much quicker. The same scenario
plays out in your local supermarket. The bigger the crowd is, the
greater the number of manned checkout counters.
You can implement the same mechanism inside your services. When
load increases, add to the number of frontends and worker processes
independently. You can also flexibly allocate resources by monitoring
the length and nature of your queues. For example, high-priority items
could be placed in a separate queue. Work items that require a large
amount of resources could be placed in their own queue, and then be
picked up by a dedicated set of worker nodes. The variations are
endless, and unique to your application.
3. Load Leveling
Load leveling is similar to scaling out. Load and stress for a system
vary constantly over time. If you provision for peak load, you are
wasting resources, since that peak load may show up only rarely. Also,
having several virtual machines in the cloud spun up and waiting for
load that isn’t there goes against the cloud philosophy of paying only
for what you use. You also need to worry about how quickly the load
increases—your system may be capable of handling higher load, but not a
very quick increase.
Using queues, you can queue up all excess load and maintain your
desired level of responsiveness. Since you’re monitoring your queues and
increasing your virtual machines (or other resources when running
outside the cloud) on demand, you also don’t have to worry about
designing your system to always run at peak scale.
A good production example of a system that uses all of these
principles is SkyNet from SmugMug.com. SmugMug is a premier
photo-sharing site hosted on Amazon Web Services. Though it uses
Amazon’s stack, all of its principles and techniques are applicable to
Windows Azure as well. It uses a bunch of queues into which the
frontends upload jobs. Its system (codenamed SkyNet, after the AI entity
in the Terminator movies) monitors the load on the
job queues, and automatically spins up and spins down instances as
needed.
Note:
You can find details on SkyNet at http://blogs.smugmug.com/don/2008/06/03/skynet-lives-aka-ec2-smugmug/.